Model-based testing (MBT): quick overview

For some time I have heard about model-based testing technique and I wanted to know a bit more about it. I will share my learnings in several posts to make digestable. In this article I will give a high-level overview of model-based testing and some initial doubts and preliminary findings along with resources.
A couple of weeks ago, I was lucky to be able to attend an online workshop from Black-Box Software Testing on State Model Based Testing. The workshop instructors (Alexandru Rotaru and Dorin Oltean) conceived it as being hands-on, which was great because makes learning more efficient.
In the first day we spent some time modeling a simple web application; in the second one, we implemented test automation code to support our model. Actually, we implemented the coded as a group using Ensemble Programming practice. We were lucky to have Maaret Pyhäjärvi also attending, which was great as introduced this concept to us and we all were able to see its benefits in practice.
What is State Model-Based Testing?
If we look at the following model, we can easily understand in few seconds that we're talking about requesting an Uber and there are certain actions we can do meanwhile, that may affect or not the state, whatever it means.
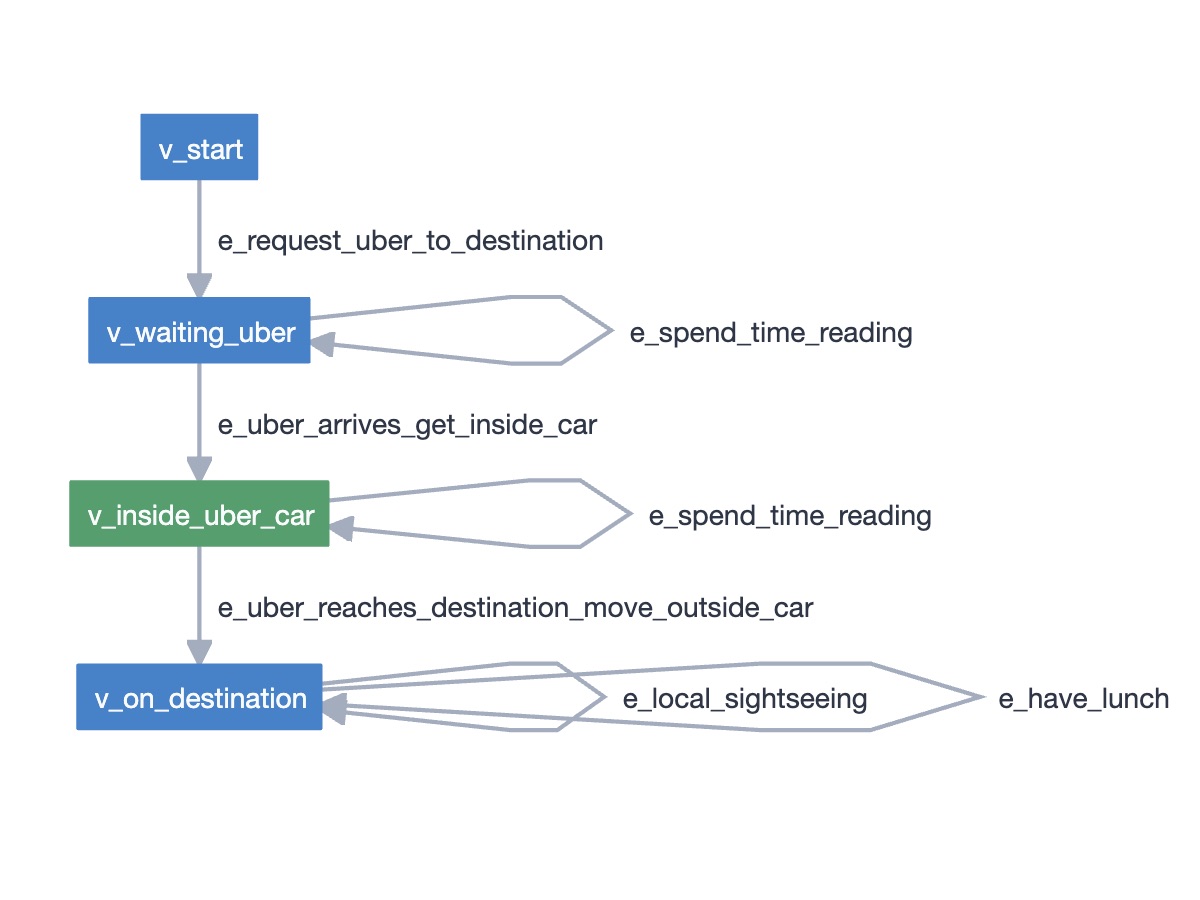
This is the power of visual models.
MBT (Model-Based Testing) is a testing technique that uses models as basis. A model is a "formal, simplified representation of a relationship, a process or a system" (quoting Alex Rotaru).
In other words, we can see that MBT:
- it's a formalization
- it's a way to describe something relevant to the system and its usage/behavior
- it's not exhaustive (i.e. it's not totally accurate)
- it's focused on testing, although we can see similirities to DDD (Domain Driven Development)
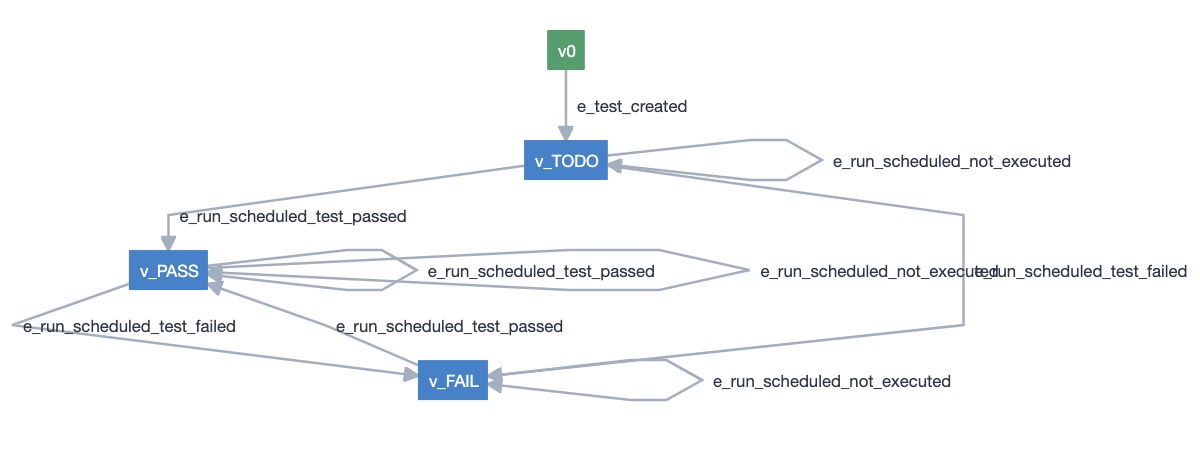
In SMBT models are built as directed graphs, composed of states (i.e. vertices) and transitions (i.e. edges). This way, it's easy to visualize and have a discussion around it.
After we build out our model, we use a tool to generate a skeleton for our test automation code. The actual test code needs to be implemented (some commercial tools provide this ability to an extent).
Finally, we can run tests exercising our model. The idea is to go over the vertices (states) in the model using the possible edges (transitions/actions) and use is that in a way that maximizes coverage; I'm oversimplifying it though. To "walk" in the model (i.e. to go from one vertex to another one using a specific edge), we need to have a "path". The MBT tool can generate an incredible high number of paths, using a "generator" algorithm, and stopping it when a certain "stop condition" is achieved.
And that's it: we have now a way to perform interactions in our SUT accordingly to the model we've defined earlier.
Note however that MBT can be used even without automation as a way to talk about the system behavior and support manual testing activities (scripted or even exploratory).
Why Model-Based Testing?
But why do we need MBT after all?
Well, if we think on any system (web or non-web based), it's really hard to test all possible usage scenarios.
Implementing traditional test automation, implementing a test script one after another for validating a specific use case takes considerable time. And more than that: their coverage will always be limited, even if we use data-driven testing.
Therefore, MBT is an excellent technique to increase coverage through more diversified test scenarios. It can also be used to quickly understand legacy systems without having to deep dive into the code specifics.
Doubts
I had a bunch of doubts at start, as usual.
- When should I use SMBT?
- What are the scenarios where SMBT is not the best fit?
- What can we map as being a vertex (i.e. a "state")?
- What are the edges (i.e. the "transitions")?
- Where should we implement the assertions?
- Semantically, what is the test scope here? An automated test script exercises a specific use case, and what happens with MBT?
- What's the relation to requirements, features, user stories?
Some of these doubts are starting to fade away as I go through real experiments but there's no right/wrong answers for most of them.
Meanwhile, several doubts arise. One that is not yet totally clear to me is related to state management:
- Where to deal with it? In the model susing the vertices themselves, as variables set in the model, or as internal variables managed in the underlying test automatiob code? Where's the border?
Modeling and its challenges
What we do when we test is to create a model of our systems in our brain and then we refine it through experimentation and validation.
This model is not unique, though.
Imagine yourself, for a moment, talking about some dream house that you've seen and that you would love to buy. Now think about someone else talking about that same house.
Do you think that you would be looking at it from the same perspective? Or would each individual see themselves having their own experiences, mostly different, in that house? More, one could think on the house as either being "under construction", "ready for living", or "inhabited" while the other one could think on it as being "with people resting", "having a party", "having lunch", etc.
Therefore, how we model a system can be done in many ways. But where to start?
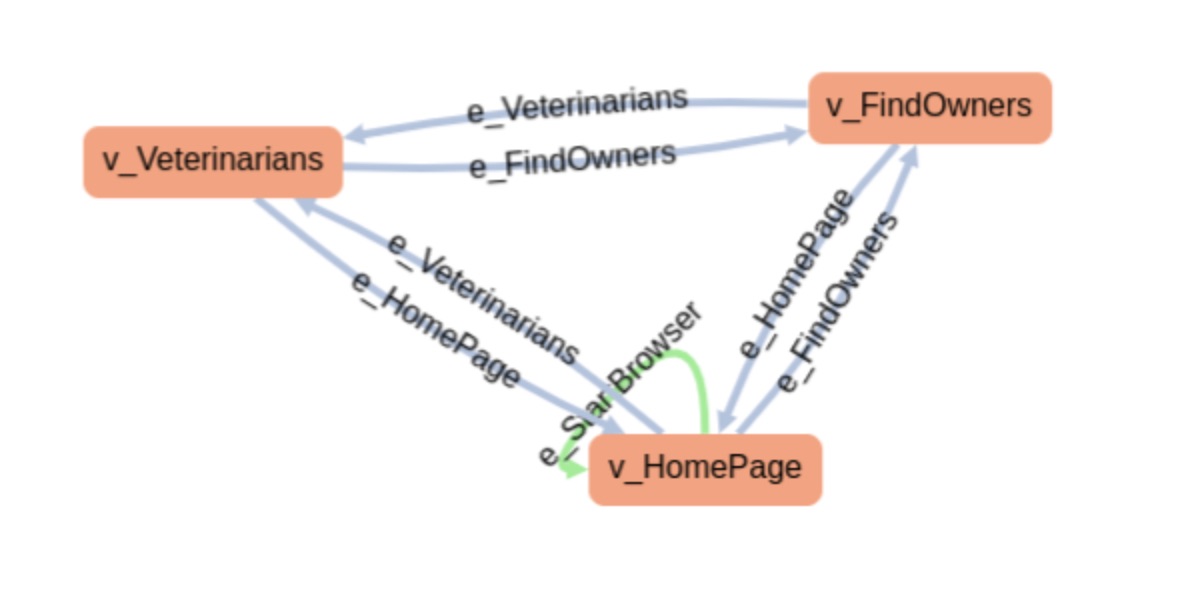
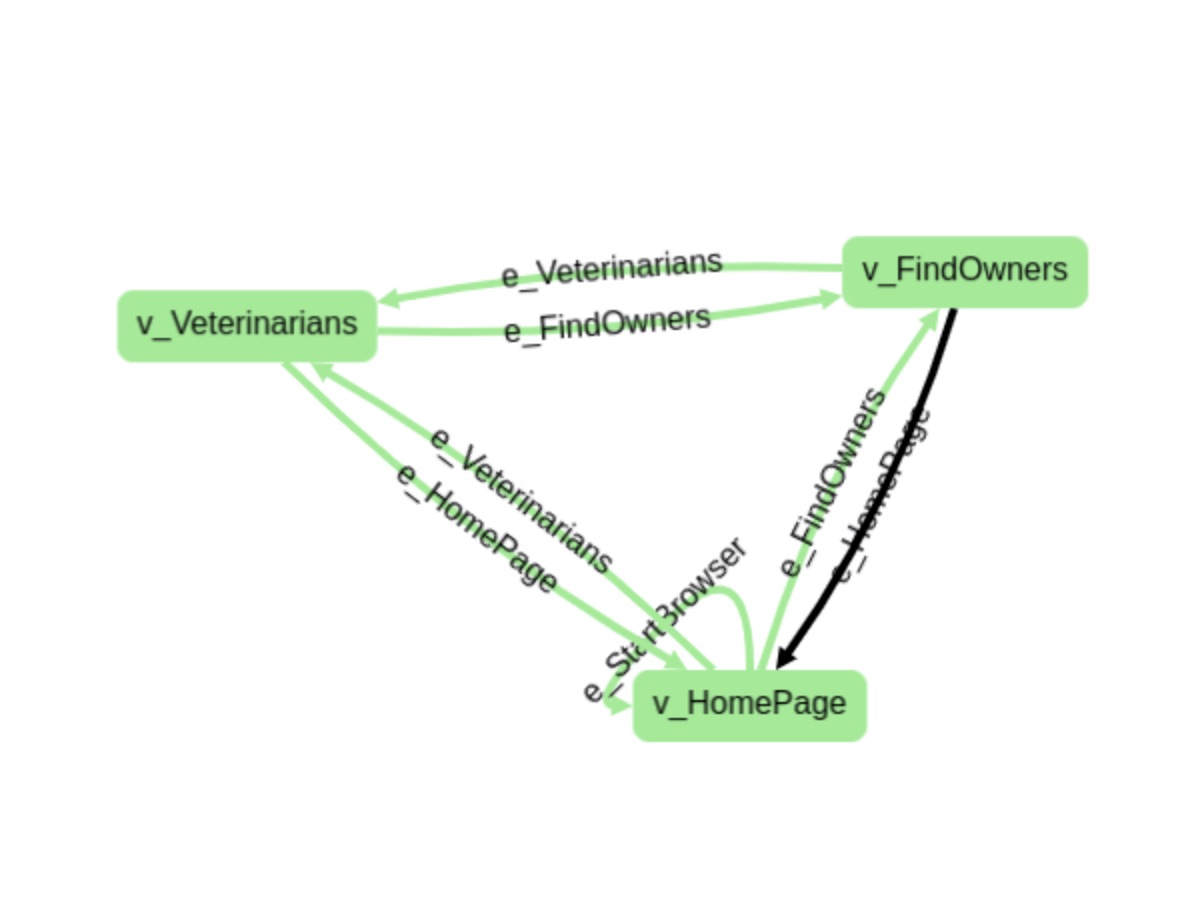
If we have a website (e.g e-commerce site), we can model it from the UI perspective, where each state corresponds to a page. Transitions are made through interactions users make (e.g. go to homepage, find owners).
However, this is not the only possible modeling approach; we can think on the state of a transaction and model that for example. So, yes, we can use MBT to model beyond just UI interactions and use it to model algorithms, for example.
Modeling requires experience because it's a simplification on reality based on a perspective that matters. All of that is subjective, have you noticed?
MBT and unknowns
Testing is about learning, learning more about what we're building, why we're building, how its being built, and how users tasting that special "meal" that is our product. Does it taste well? Is it missing something? Was it delivered at the right time, to the right users?
Well, with testing we try to uncover all these unknowns that surround our products and that live inside them. Model-based testing can be used as a great technique to expose some unknowns and confirm certain behaviors of our products.
Models are easy to understand and visualize, and also can be easy to automate and check. By writing an executable model, we can (in)validate assumptions and then refine it. We can even fork and create additional models to tackle different aspects.
Modeling has also one interesting consequence: it promotes discussion. By promoting discussion, unknowns can be tackled on people's heads. Therefore, pairing or doing it as a group (ensemble programming) can provide additional benefits.
Tooling
There are several tools out there, including open-source ones. Probably the most popular is GraphWalker, which is tailored for Java skilled users (as it generates Java code and then can run it).
Python and C# users may prefer to use AltWalker instead. AltWalker uses GraphWalker on the backstage.
Commercial tools are also available; I've seen some but not yet tried them myself. I would say that there are at least two great differences:
- visual editors are better
- test automation code generation supports many more languages and frameworks
Tips
If you are new on this topic, I already have some tips that may be useful.
- Don't try to make complex models as they will be hard to read and maintain
- Have few vertices and edges; focus on the essential
- Spliting the model in several and use shared states, if it makes sense
- Even if we're talking about the same feature, having different models can provide different angles to it and to expose different bits of it
Learn more
I would recommend the following resources to get your hands dirty :) Any of the two examples is simple to understand and to get running.
If you want to know more about some specific open-source tools, that also talk a bit about the rational of model-based testing, please check:
- GraphWalker => the wiki pages on Github provide several examples and explain concepts
- AltWalker
- Visual model editor for AltWalker and GraphWalker
- AltWalker Model Visualizer for VSCode
Thanks for reading this article; as always, this represents one point in time of my evolving view :) Feedback is always welcome. Feel free to leave comments, share, retweet or contact me. If you can and wish to support this and additional contents, you may buy me a coffee ☕